Overview
⚠️ Warning:
The latest version ofPFD-kitintegrates with the ASE package, enhancing functionality and compatibility with modern workflows. Users are encouraged to transition to this version for the best experience. The older version remains available for access.
PFD-kit automates the fine-tuning and distillation of pre-trained atomic models, such as DPA-2. It enables practical atomistic simulations with highly transferable but computationally expensive pre-trained models. Built on DPGEN2, PFD-kit supports Deep Potential models and is optimized for the Bohrium platform.
Background
Machine learning force fields (e.g., Deep Potential) combine quantum mechanics with data-driven algorithms to enable large-scale atomic simulations with first-principle accuracy. However, they often face challenges like limited transferability, high data generation costs, and extensive human intervention during training, making them resource-intensive.
Figure 1 illustrates two challenging material systems:
Carbon materials: While bulk carbon with small unit cells is manageable, surface structures or disordered phases require large supercells and extensive sampling, making training nearly intractable.
High-entropy alloys: The spatial arrangement of atoms of different elements leads to varying interactions. As the number of elements increases, the chemical space grows exponentially, complicating comprehensive sampling.

Figure 1. Typical material systems that challenge force field training.
Large atomic models (LAMs), such as DPA-2, pre-trained on extensive datasets, embed transferable knowledge across vast chemical and configuration spaces. Fine-tuning these models for specific material domains requires significantly smaller datasets—often one-tenth or even one-hundredth of the data needed for training from scratch. Fine-tuned models achieve DFT-level accuracy at lower costs, replacing DFT for efficient data sampling and labeling.
Knowledge distillation further transfers the fine-tuned model’s knowledge to a lightweight Deep Potential model with fewer parameters. This distilled model maintains accuracy within a specific domain while being suitable for large-scale simulations involving millions of atoms over long timescales (e.g., nanoseconds). Applications include two-dimensional materials, metamaterials, semiconductors, energy materials, and alloys.
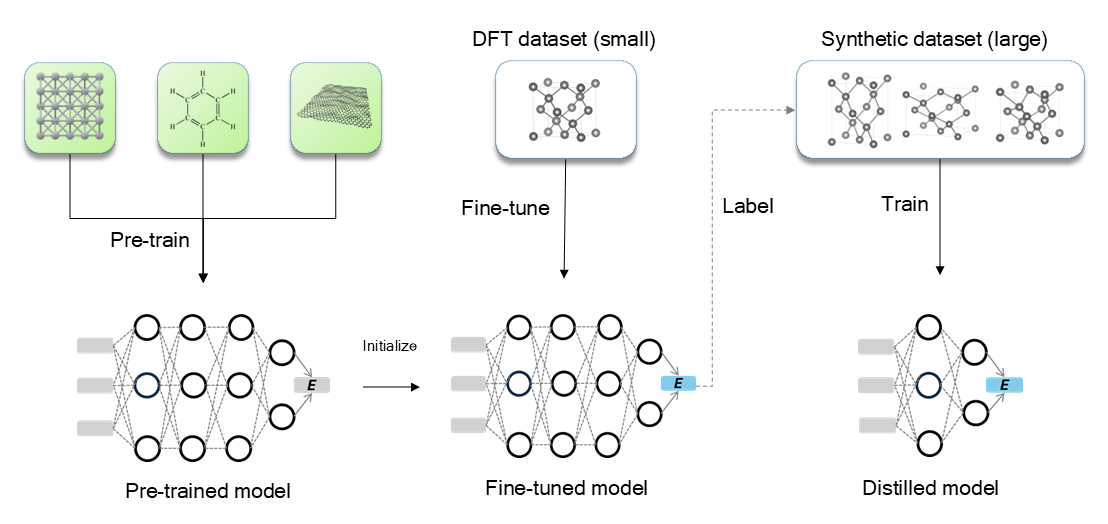
Figure 2. The general concept of the PFD-kit workflow.
PFD-kit streamlines this process, automatically generating an end model from a pre-trained model (P) through fine-tuning (F) and distillation (D). Compared to traditional methods, PFD-kit reduces the time and computational costs of force field generation by an order of magnitude, requiring minimal human intervention. This significantly accelerates high-throughput computing and complex material simulations.
Workflows
The PFD-kit workflow includes fine-tuning and distillation components, incorporating data-selection algorithms that maximize efficiency using entropy-based measures of atomic environments.

Figure 3. Schematics of the PFD-kit workflow.
Citing
If you use PFD-kit in a publication, please cite the following paper:
@misc{wang2025pfdkit,
author = {Ruoyu Wang, Yuxiang Gao, Hongyu Wu and Zhicheng Zhong},
title = {Pre-training, Fine-tuning, and Distillation (PFD): Automatically Generating Machine Learning Force Fields from Universal Models},
year = {2025},
eprint = {arXiv:2502.20809},
archivePrefix= {arXiv},
primaryClass = {cond-mat.mtrl-sci},
url = {https://arxiv.org/abs/2502.20809}
}